
OpenAI, Anthropic, Gemini APIs — Context Windows, Cost vs Capability Trade-offs, Batching, Streaming, Vision
Why Model Selection Makes or Breaks Your AI Agent
Choosing the right LLM and using its API efficiently is one of the highest-leverage decisions in production AI engineering. The wrong model choice can mean 10x higher cost, 3x higher latency, or unacceptable quality degradation. The right choice — matched to task requirements, cost budget, and latency SLA — is what separates engineers who build production systems from those who build demos.
This topic covers the major provider APIs (Anthropic, OpenAI, Google), their unique capabilities and constraints, model selection frameworks for different task types, and the engineering patterns — batching, streaming, caching, fallbacks — required to run LLM APIs reliably at production scale.
| Core question: How do you select the right model for each task type, use its API efficiently, control costs, and ensure reliability — at production scale with real SLA requirements? |
Agentic LLM Model Selection Guide
2. Provider API Landscape
2.1 Anthropic Claude API
Claude’s primary strengths are instruction following, long-context fidelity, structured output reliability, and extended thinking. The API is clean and well-documented with a few Claude-specific features every engineer must know.
| Claude-specific features critical for production: Extended Thinking: max_thinking_tokens parameter — model reasons in a separate thinking block Prompt Caching: cache_control: {type: ‘ephemeral’} on any content block (5-minute cache) Batch API: process up to 10,000 requests asynchronously at 50% cost discount Token-efficient tool use: auto-compresses tool definitions to reduce prompt tokens Computer use beta: screenshot-based UI automation (Claude 3.5 Sonnet) |
| Anthropic prompt caching pattern import anthropic client = anthropic.Anthropic() response = client.messages.create( model=’claude-sonnet-4-20250514′, max_tokens=1024, system=[{ ‘type’: ‘text’, ‘text’: LARGE_SYSTEM_PROMPT, # 5000+ tokens — cache this ‘cache_control’: {‘type’: ‘ephemeral’} # Cache for 5 minutes }], messages=[{‘role’: ‘user’, ‘content’: user_query}] ) Check cache usage in response print(response.usage.cache_read_input_tokens) # tokens served from cache print(response.usage.cache_creation_input_tokens) # tokens written to cache |
2.2 OpenAI API
OpenAI’s strength is ecosystem maturity, the widest adoption, and the o-series reasoning models. The GPT-4o family has the best function calling reliability and the o-series models (o1, o3) deliver the best complex reasoning quality.
| OpenAI-specific features critical for production: Structured Outputs (strict mode): Guaranteed JSON schema compliance — use always for data extraction Batch API: 24-hour async processing at 50% discount. Best for offline evaluation and bulk processing Assistants API v2: managed thread storage, retrieval, code interpreter — good for stateful conversations Realtime API: WebSocket-based low-latency audio+text (GPT-4o-realtime) for voice agents reasoning_effort: low/medium/high on o3-mini — controls cost vs quality for reasoning models |
2.3 Google Gemini API
Gemini’s primary differentiators are the massive 1M-token context window (Gemini 1.5 Pro), native multimodal capabilities (text, image, audio, video in a single call), and Google infrastructure advantages for GCP-native stacks.
- Flash 2.0: Best price-per-token for high-volume tool calling. 1M context at Flash speed and cost — ideal for long document analysis pipelines.
- Grounding with Google Search: Native integration — model automatically searches and cites sources. Eliminates need for custom RAG for general knowledge queries.
- Live API: Bidirectional streaming for real-time audio/video processing. Direct competitor to OpenAI Realtime API.
3. Model Selection Framework
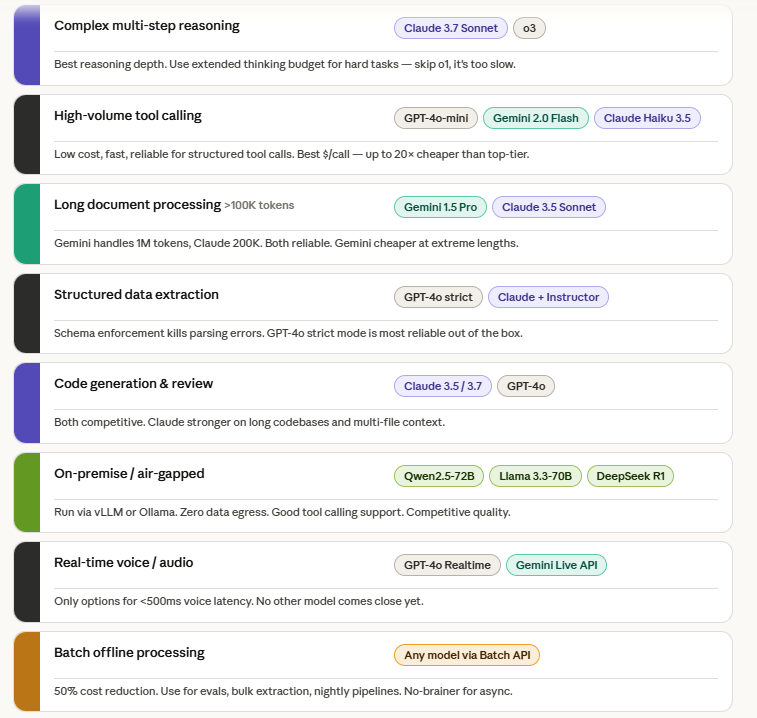
3.1 Task-to-Model Mapping
| Task Type | Recommended Model(s) | Rationale |
| Complex multi-step reasoning | Claude 3.7 Sonnet (Extended Thinking) / o3 | Best reasoning depth. Use extended thinking budget for difficult tasks. |
| High-volume tool calling | GPT-4o-mini / Gemini 2.0 Flash / Claude Haiku 3.5 | Low cost, fast, reliable for structured tool calls. Best $/call. |
| Long document processing (>100K tokens) | Gemini 1.5 Pro / Claude 3.5 Sonnet | Both handle 1M/200K context reliably. Gemini cheaper for extreme lengths. |
| Structured data extraction | GPT-4o with strict structured output / Claude + Instructor | Schema enforcement eliminates parsing errors. GPT-4o strict mode most reliable. |
| Code generation & review | Claude 3.5/3.7 Sonnet / GPT-4o | Claude and GPT-4o competitive. Claude stronger on long codebases. |
| On-premise / air-gapped | Qwen2.5-72B / Llama 3.3-70B / DeepSeek R1 | Run locally via vLLM or Ollama. No data egress. Good tool calling support. |
| Real-time voice/audio | GPT-4o Realtime / Gemini Live API | Only options for <500ms latency voice interaction. |
| Batch offline processing | Any model via Batch API | 50% cost reduction. Use for evals, bulk extraction, nightly processing. |
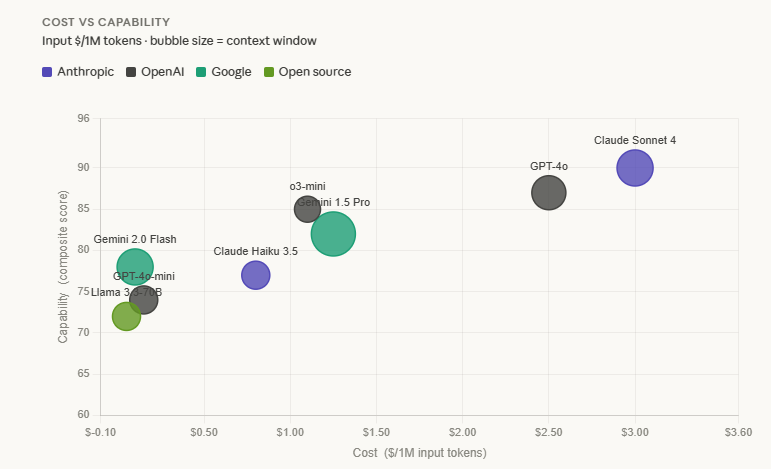
3.2 Cost vs Capability Trade-off Matrix (2025 Pricing, approximate)
| Model | Input $/1M tokens | Best For |
| GPT-4o | $2.50 | Production tool calling, structured output, vision |
| GPT-4o-mini | $0.15 | High-volume routing, classification, simple tool calls |
| o3-mini (medium effort) | $1.10 | Reasoning tasks that need o1-quality at lower cost |
| Claude Sonnet 4 / 3.7 | $3.00 | Complex reasoning, long context, instruction following |
| Claude Haiku 3.5 | $0.80 | Fast responses, high-volume agents, routing decisions |
| Gemini 1.5 Pro | $1.25 (up to 128K) | Long doc processing, multimodal, GCP-native stacks |
| Gemini 2.0 Flash | $0.10 | Cheapest capable model. High-volume pipelines. |
| Llama 3.3-70B (self-hosted) | ~$0.05 (infra cost) | On-premise, no data egress, air-gapped environments |
4. Production API Patterns
4.1 Streaming
Always use streaming for user-facing responses. Streaming begins delivering tokens as they are generated — dramatically improving perceived latency even when total generation time is the same.
| # Anthropic streaming with event processing with client.messages.stream( model=’claude-sonnet-4-20250514′, max_tokens=1024, messages=[{‘role’: ‘user’, ‘content’: query}] ) as stream: for event in stream: if event.type == ‘content_block_delta’: if eAnthropic streaming with event processing with client.messages.stream( model=’claude-sonnet-4-20250514′, max_tokens=1024, messages=[{‘role’: ‘user’, ‘content’: query}] ) as stream: for event in stream: if event.type == ‘content_block_delta’: if event.delta.type == ‘text_delta’: print(event.delta.text, end=”, flush=True) elif event.delta.type == ‘thinking_delta’: # Extended thinking # Optionally display thinking or log for debugging pass elif event.type == ‘message_stop’: final_message = stream.get_final_message() |
4.2 Batch Processing
For workloads where real-time response is not required — evaluation runs, bulk data extraction, nightly processing, offline report generation — use the Batch API for 50% cost reduction with no quality difference.
- Anthropic Batch API: Submit up to 10,000 requests in a single batch. Results available within 24 hours. Ideal for bulk 3GPP spec processing, eval harnesses, nightly KPI report generation.
- OpenAI Batch API: Same economics. 24-hour SLA. Use for bulk fine-tuning data preparation, classification of large datasets, offline customer churn scoring.
- Cost example: Processing 10,000 pages of Huawei HedEx manuals via Claude Sonnet for structured extraction: ~$15 via Batch API vs ~$30 via standard API.
4.3 Reliability Patterns — Fallbacks & Load Balancing
Production LLM API usage requires resilience engineering. No provider has 100% uptime and rate limits constrain throughput at scale.
| Pattern | Implementation |
| Provider fallback | Primary: Claude Sonnet. Fallback: GPT-4o. Detect 529/rate-limit errors and retry against fallback with same prompt. |
| Model tier fallback | On timeout or rate limit: retry with faster/cheaper model (e.g. Haiku instead of Sonnet). Accept quality reduction for availability. |
| Rate limit management | Implement token bucket per API key. Track input+output tokens per minute. Back off exponentially on 429s with jitter. |
| Response caching | Cache identical or semantically-similar prompts with short TTL. Semantic cache (e.g. GPTCache) hits ~30% on repeated queries in enterprise settings. |
| Circuit breaker | If provider error rate exceeds threshold (e.g. >5% in 60s), open circuit and return degraded response rather than queuing failed requests. |
4.4 Vision & Multimodal APIs
All major providers support image input alongside text. Critical for agents processing diagrams, screenshots, charts, and scanned documents.
- Image encoding: Pass images as base64 or URL. URL preferred for large images to avoid prompt token inflation. Images cost additional tokens — a 512×512 image is ~170 tokens (Claude) to ~250 tokens (OpenAI).
- Document processing: For PDF/document analysis, Claude’s document beta supports direct PDF upload. For other providers, convert pages to images. Gemini accepts native PDF via file upload API.
- Vision for agents: Combine vision with tool calling for screen-reading agents. Claude Computer Use provides a full screen automation framework built on vision + tool calling.
5. Common Issues & Pitfalls
| Issue | Cause & Fix |
| Rate limit exhaustion | Not tracking token usage per minute. Fix: implement token counting before each call; queue and delay if approaching limit. |
| Context window overflow | Passing full conversation history indefinitely. Fix: summarise history beyond last N turns; remove completed tool call chains. |
| Model version drift | Using ‘gpt-4’ (auto-upgraded) causes silent behaviour changes. Fix: pin to specific model versions in production (e.g. ‘gpt-4o-2024-11-20’). |
| Cost overruns | No per-request token budget; expensive models used for cheap tasks. Fix: per-task model routing; hard max_tokens limits; daily cost alerts. |
| Latency spikes | Synchronous API calls blocking UI. Fix: streaming for user-facing; async/background for batch tasks. |
| Vendor lock-in | All prompts rely on provider-specific features. Fix: abstract LLM calls behind provider-agnostic interface (LiteLLM, LangChain); test with 2+ models. |
6. Expert Tips & Quick Reference
- Pin model versions in production — never use ‘gpt-4’ or ‘claude-3-sonnet’ without a date version. Auto-upgrades silently change behaviour and break evals.
- Use the Batch API for any workload that doesn’t need real-time response. 50% cost reduction with zero effort is the best ROI in LLM engineering.
- Implement a model routing layer: cheap models for classification/routing, expensive models for reasoning. This single pattern typically reduces LLM cost by 60-70% in production.
- In interviews: discuss the cost vs latency vs quality triangle with specific numbers. Candidates who can say ‘Haiku is $0.80/1M vs Sonnet at $3.00/1M for this use case’ stand out immediately.
- For GCC/telecom enterprise: data residency matters. Anthropic and Google offer regional endpoints; for truly sensitive data, Llama/Qwen on on-premise vLLM eliminates all egress risk.
- Track token usage per user/tenant in multi-tenant systems. Without usage attribution, cost overruns are invisible until the bill arrives.