
The 7-Layer Model — A Complete Technical Guide How modern AI agents perceive, reason, act, and self-correct
What Is an Agentic AI System?
An AI agent is not just a chatbot that answers questions. It is a software system that can pursue a goal autonomously across multiple steps — perceiving its environment, forming a plan, selecting tools, executing actions, observing results, and adjusting course without constant human instruction. The shift from a simple LLM call to a production-ready agentic system requires an architectural model that organises these capabilities into distinct, manageable layers.
The 7-Layer Agentic AI Model provides that structure. Each layer has a single responsibility, a clear set of components, and defined interfaces to the layers above and below it. Together they form a complete stack — from raw inputs at the bottom to high-level goals at the top — that any engineering team can reason about, build against, and extend.
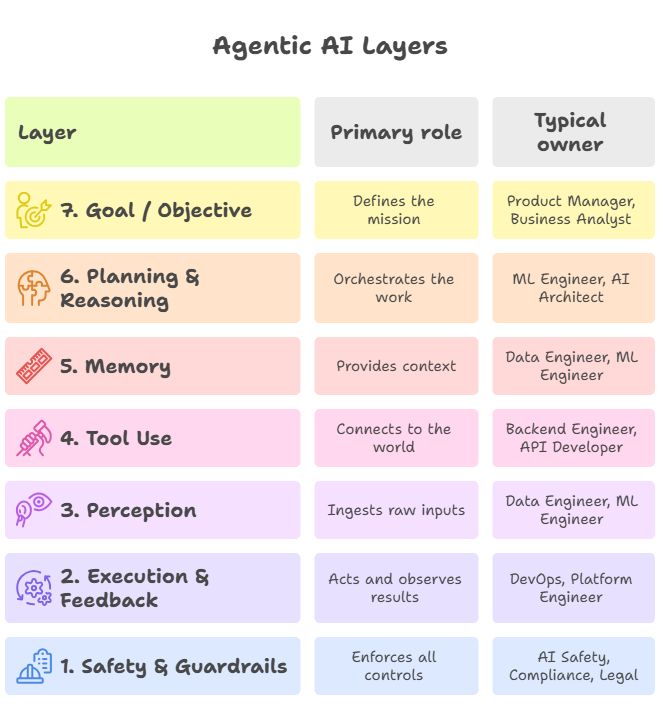
The 7 Layers at a Glance
The table below maps each layer to its primary role and the team function typically responsible for building and maintaining it.
Layer-by-Layer Breakdown
Layer 7 — Goal / Objective Layer
The Goal Layer sits at the top of the stack and defines what the agent is trying to achieve. It is the ‘why’ behind every decision made in the layers below. Without a clear goal, no amount of sophisticated planning or tool-calling produces meaningful outcomes.
Goals can be set in several ways. A human operator may configure them explicitly — ‘resolve all open support tickets with a CSAT score above 4’ — or another orchestrating agent in a multi-agent system may delegate sub-goals dynamically. In more advanced deployments, a policy engine derives goals automatically from business rules, SLA thresholds, or real-time KPIs.
The Goal Layer also carries constraints: time budgets, cost ceilings, compliance boundaries, and ethical policies. These constraints shape every downstream decision. A well-designed Goal Layer makes them explicit and machine-readable so that the Planning Layer can reason over them directly.
Key responsibilities of the Goal Layer:
- Translates business intent into a structured objective the agent can act on
- Carries constraints such as deadlines, budgets, and compliance requirements
- Supports goal decomposition for multi-agent systems where one agent spawns others
- Provides the success criteria used by the Execution Layer to know when to stop
Layer 6 — Planning & Reasoning Layer
The Planning Layer is where the LLM’s intelligence does its core work. Given a goal and its constraints, this layer breaks the problem into sub-tasks, selects a reasoning strategy, decides which tools to invoke and in what sequence, and re-plans whenever a tool call fails or returns unexpected results.
Several reasoning patterns operate at this layer. ReAct (Reason + Act) interleaves chain-of-thought reasoning with tool calls, allowing the agent to update its plan at each step. Tree-of-Thought explores multiple solution branches in parallel before committing. Plan-and-Execute separates the planning phase from execution, generating a full task graph upfront and then running it — useful when individual steps are expensive or irreversible.
Orchestration frameworks such as LangGraph, CrewAI, and AutoGen implement this layer. LangGraph is particularly well-suited to production systems because it models the agent’s reasoning as an explicit stateful graph, making branching, looping, and error recovery predictable and observable.
Key responsibilities of the Planning Layer:
- Decomposes complex goals into ordered, executable sub-tasks
- Selects and applies the appropriate reasoning strategy for each situation
- Manages the agent’s inner loop: think, act, observe, re-plan
- Routes tasks to specialised sub-agents in multi-agent architectures
- Handles failures gracefully by detecting dead ends and generating recovery plans
Layer 5 — Memory Layer
An agent without memory is stateless — it can only act on what fits in a single prompt window. The Memory Layer extends the agent’s context across steps, sessions, and even deployments, giving it the ability to learn from past interactions and bring domain knowledge to bear on new problems.
Memory in agentic systems comes in four distinct forms. In-context memory is simply the active prompt window — fast, always available, but limited in size. Episodic memory persists structured records of past agent runs in a vector database, allowing the agent to recall what it tried, what worked, and what failed. Semantic memory stores domain knowledge — documentation, policy handbooks, product catalogs — that the agent retrieves via RAG when relevant. Procedural memory captures learned behaviours and preferences that shape how the agent approaches recurring task types.
Popular implementations include ChromaDB, Pinecone, and Weaviate for vector storage; Redis for fast episodic caching; and embedding models such as OpenAI text-embedding-3 or open-source alternatives like BAAI/bge for semantic search. The CrossEncoder reranker is commonly used to improve the precision of retrieved passages before they enter the prompt.
Key responsibilities of the Memory Layer:
- Maintains in-context state across the steps of a single agent run
- Persists episodic records of past runs for retrospection and debugging
- Provides semantic retrieval of domain knowledge via RAG pipelines
- Stores procedural preferences that shape agent behaviour over time
- Manages context window limits through summarisation and selective retrieval
Layer 4 — Tool Use Layer
A language model on its own can only produce text. The Tool Use Layer is what connects an agent to the real world — APIs, databases, code executors, web browsers, third-party services, and other agents. Every concrete action the agent takes flows through this layer.
Tools are exposed to the LLM through a structured function-calling interface. The model receives a list of available tool signatures — name, description, parameters, return type — and decides when and how to invoke each one. Well-designed tool descriptions are critical: an ambiguous or overly broad description causes the model to call the wrong tool or pass incorrect arguments.
Common tools include REST API clients, SQL query executors, Python code sandboxes, web search engines, file system readers and writers, email and calendar integrations, and sub-agent invocations. In production systems, each tool call is wrapped in retry logic, timeout handling, and rate-limit management. Tool outputs are always returned as structured observations that the Planning Layer can reason over in the next step.
Key responsibilities of the Tool Use Layer:
- Exposes external capabilities to the LLM via structured function signatures
- Handles authentication, rate limiting, retries, and timeouts for every tool call
- Sandboxes code execution to prevent unintended side effects
- Formats tool outputs as structured observations for the Planning Layer
- Manages parallel tool calls when multiple actions can be taken simultaneously
Layer 3 — Perception Layer
Before the agent can reason, it must understand its environment. The Perception Layer ingests raw signals from the outside world and converts them into a form the LLM can process — tokens, embeddings, or structured data objects.
Inputs vary widely by domain. A customer service agent might ingest free-text chat messages and CRM records. A document processing agent handles PDFs, spreadsheets, and images. A system monitoring agent consumes structured log streams, metric time series, and alert payloads. In all cases, the Perception Layer is responsible for normalisation, deduplication, chunking, and quality filtering before any data reaches the Planning Layer.
For multimodal agents, this layer also handles vision inputs via image encoders, audio via speech-to-text transcription, and video via frame sampling. The output is always a clean, contextualised representation that the Planning Layer can immediately reason over without needing to handle raw format conversion.
Key responsibilities of the Perception Layer:
- Ingests inputs across all modalities: text, structured data, images, audio, streams
- Normalises, deduplicates, and quality-filters raw signals before they enter the model
- Chunks large documents into segments sized for the model’s context window
- Converts raw signals into embeddings for semantic similarity and retrieval
- Handles real-time streaming inputs for low-latency agent applications
Layer 2 — Execution & Feedback Layer
Planning is only useful if action follows. The Execution Layer takes the decisions made by the Planning Layer and carries them out in the real world, then captures the results and feeds them back as observations so the loop can continue.
This layer manages the full action lifecycle: issuing API calls, writing to databases, triggering webhooks, sending messages, updating records. It also handles partial failures — tracking which actions succeeded, which failed, and which produced ambiguous results — and surfaces that information in a structured format the Planning Layer can use to decide whether to retry, reroute, or escalate.
The feedback half of this layer is as important as the execution half. Without accurate, timely observations, the agent cannot correct its course. Well-designed feedback includes not just the raw output of an action but also its latency, confidence score, and any warnings or side effects. This richer signal enables the Planning Layer to make much better re-planning decisions.
Key responsibilities of the Execution & Feedback Layer:
- Executes actions decided by the Planning Layer in the correct sequence or in parallel
- Tracks action state: pending, succeeded, failed, ambiguous
- Formats execution results as structured observations for the planning loop
- Manages idempotency to prevent duplicate actions on retries
- Triggers human-in-the-loop escalation when actions exceed risk thresholds
Layer 1 — Safety & Guardrails Layer
The Safety Layer does not sit at the bottom of the stack in the sense of being least important. It cross-cuts every other layer. Its rules are enforced at every transition — before a plan is executed, before a tool is called, before an output is returned to a user, and before a sub-agent is spawned.
Safety in agentic systems is harder than safety in single-turn LLM calls because the attack surface is larger. The agent interacts with external APIs, executes code, reads and writes persistent storage, and potentially controls real-world systems. A misconfigured tool description, a prompt injection in a retrieved document, or a runaway retry loop can all produce serious unintended consequences. The Safety Layer exists to catch and contain these failure modes before they propagate.
Core mechanisms include output filtering (blocking harmful or non-compliant text), input sanitisation (stripping prompt injections from external data), cost budget enforcement (halting the agent before it exceeds a token or API cost ceiling), rate limiting, and human-in-the-loop checkpoints at high-stakes decision points. Increasingly, compliance requirements — GDPR, HIPAA, SOC 2 — mandate that the Safety Layer also produce an auditable log of every significant agent decision.
Key responsibilities of the Safety & Guardrails Layer:
- Filters all inputs and outputs against a defined set of content policies
- Sanitises external data to prevent prompt injection attacks
- Enforces token, API call, and monetary cost budgets across the full agent run
- Inserts human-in-the-loop checkpoints at irreversible or high-risk actions
- Generates an auditable log of all significant agent decisions for compliance
- Detects and halts runaway loops, infinite retries, and cascading failures
How the Layers Connect
The 7 layers do not operate in strict sequential order. The agent’s inner loop — perceive, plan, act, observe, re-plan — cycles through layers 2 through 6 repeatedly until the goal is met or a termination condition is reached. Layer 7 (Goal) is set before the loop begins and consulted throughout. Layer 1 (Safety) is checked at every transition without exception.
Why This Model Matters for Engineering Teams
The 7-layer model is not just conceptual scaffolding. It has practical consequences for how teams design, build, test, and operate agentic systems.
Separation of concerns.
Each layer has a single responsibility. This means failures are localised — a flaky tool in Layer 4 does not corrupt the memory in Layer 5 or compromise the safety checks in Layer 1. Teams can develop and test each layer independently, and swap out implementations (e.g. replacing one vector store with another) without touching adjacent layers.
Observability.
Because the layer boundaries are explicit, every inter-layer call can be instrumented. Engineers can trace exactly what the agent perceived, what plan it formed, which tools it called, what it observed, and why it re-planned. This is essential for debugging non-deterministic agentic behaviour.
Scaling complexity.
Simple agents may initially collapse several layers into a single Python function. The 7-layer model gives teams a growth path — as requirements evolve, they can add proper memory management, richer tool registries, or more sophisticated safety checks one layer at a time without redesigning the whole system.
Conclusion
Agentic AI systems are fundamentally different from stateless LLM calls. They operate over time, interact with external systems, manage state, and pursue goals autonomously. Without a clear architectural model, they become unpredictable and unmaintainable.
The 7-layer model — Goal, Planning, Memory, Tool Use, Perception, Execution, and Safety — provides the conceptual foundation every engineering team needs to build, reason about, and scale these systems confidently. Each layer has a clear purpose, clear ownership, and clear interfaces. Together they form a production-grade architecture that is both powerful and governable.
As agentic AI moves from research prototype to enterprise deployment, the teams that invest in this kind of structured thinking will build systems that last.